Teaching
Recurring lectures
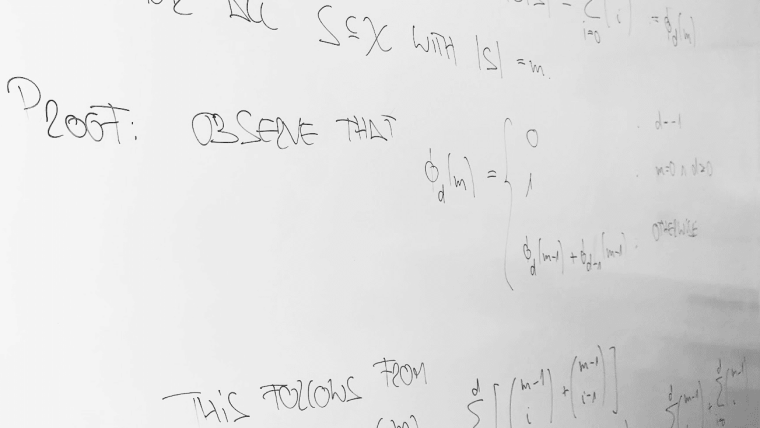
In this course, we investigate the question under which conditions learning is possible. PAC (probably approximately correct) learning theory can provide an answer to this question. The framework of PAC learning is supervised learning, in which one observes labels at features, and the goal is to predict labels at non-necessarily observed features.
The lecture is divided into four sections:
First, we look at elementary learning methods, which are essentially linear methods on a Euclidean space. In the second part of the lecture, we extend these methods non-linearly to more general feature spaces. The third part makes up the core of the lecture. We will see that in learning one can make two kinds of errors, which play against each other, namely, approximation errors and estimation errors. That is, a small estimation error often means a large approximation error and vice versa. Estimation errors can be controlled by limiting the capacity of the hypothesis classes from which the labelling functions are chosen by using observed data. However, limiting the capacity of hypothesis classes induces biases that can lead to large approximation errors. In the last part of the lecture, we derive a learning method, called support vector machine (SVM), from learning theory. SVMs have an interesting geometric interpretation that gives us further insights into the nature of learning, especially in the high-dimensional setting.
This course provides an introduction to probabilistic models and probabilistic inference. A probabilistic model on a sample space is a description of how data from this space could be generated. It can be given in expression form such as a multivariate Gaussian, or, more generally, in the form of a probabilistic program. Probabilistic models are used to inform decision-making under uncertainty in the light of partial evidence. Decision-making requires support of inference queries on the model. For example, a simple model could involve only two statements, "the sky is cloudy" and "the grass is wet", both of which can either be true or false. A probabilistic model assigns probabilities to each of the four possible scenarios ("sky is cloudy and grass is wet", etc.). The partial evidence "the sky is cloudy" changes our belief whether the grass is wet. To do the inference, we compute the conditional probability of the statement "the grass is wet", which will mostly be different from our judgment when ignoring observations of the sky, expressed by a marginal probability.
This introductory course covers basic efficient algorithms and data structures. It emphasizes correctness proofs and asymptotic run time analysis. A data structure is a representation of data that enables efficient access and modification. Typically, one needs an algorithm to build a data structure. Often the running time of the algorithm for building the data structure is larger than directly accessing the data. However, the overhead of building the data structure can pay off, or amortize, if the data is accessed more than once. The first part of the course introduces basic data structures like arrays, lists, search trees, priority queues, hash maps and sets (union-find). In the second part, these data structures are used in the design and analysis of elementary algorithms for searching, and for computing minimum spanning trees, minimum cuts, and shortest paths in graphs.
This course covers the algorithm engineering cycle that consists of algorithm design, analysis, implementation and experimental evaluation. The key idea conveyed in the course can be stated as starting simple, experimentally measuring and evaluating performance, and then addressing identified bottlenecks, where the last two steps are iterated. This process is typically supported by tools for documentation, version control, automatic build, debugging, and profiling. The course introduces such tools and their usage in small projects.